Caseopea offers a next generation document review and analysis platform that
dramatically reduces the overwhelming overhead imposed on lawyers by pre-litigation
e-Discovery.
Caseopea combines its advanced Natural Language Understanding technology with its
innovative semantic reasoning framework and knowledge-guided search engine, to deliver a
groundbreaking e-Discovery platform able to identify and extract case-related material out
of large volumes of electronic data.
The traditional Discovery process, whereby both lawsuit parties share relevant documents with each other, used to involve physically handing over boxes of papers, but no more. The advent of new forms of digital office communications has triggered dramatic changes to the civil Discovery act. The transformation of the Discovery process was accelerated by a series of amendments to the Federal Rules of Civil Procedure (FRCP), introduced by US Supreme Court as of December 2006. These amendments have largely extended the scope of admissible discovery material to include all forms of Electronically Stored Information (ESI), including e-mail, instant messages, chats, Electronic Office files (documents, presentation, spreadsheets), accounting databases, Web sites, and other electronically-stored information that could be relevant in a law suit. The Discovery process expanded scope is posing extreme challenges and opportunities for attorneys, clients, technology providers, and justice courts. Some well-known law experts have ranked the recent discovery amendments as the most significant change to the legal system in recent decades.
With massive volumes of electronic information being collected, reviewed, produced and consumed, the challenge is enormous and the effects are well noted – big firms that were used to producing half a million documents for a high stake case, would now have to process a hundred times that quantity. Moreover, the problem is not confined to staggering volumes. The new forms of electronic information are also much more complex, intertwined and fluid, making the Discovery information, saturated with cross references, much harder to follow, review and analyze.
It is therefore hardly
surprising that the cost of e-Discovery has reached astounding numbers:
A Microsoft executive has disclosed in a recent post that the company is spending an
average of US$ 20 million for e-Discovery per litigation.
The e-Discovery market is growing rapidly. A recent IDC research has found that
the cost of legal discovery and litigation support has totaled $12 billion in 2007 up 23%
from $9.7 billion in 2006. A recent survey by Socha-Gelbmann
(authoritative law technology experts) has found even more impressive growth rates: 33% in
2006 and 28% in 2007, the report is predicting growth rates well above 20% in the next few
years.
The new landscape of
e-Discovery has forced some fundamental changes in the industry. Law firms and enterprise
legal departments, considered not long ago stiff technophobes, started investing heavily
on e-Discovery and litigation support systems. The market for e-Discovery support technology is booming across
the entire technology spectrum: storage and document management systems, review and
analysis platforms, collection preservation, online processing and full service
outsourcing. Within this wide spectrum of offerings, the review and analysis step stands
out as the most expensive and risky. Compared to other steps of e-Discovery, the cost
associated with analysis and review is larger by scale. On average, it costs $1,800 to process and prepare
data for analysis, and around $200-$250 per hour to analyze and review it, where review
processes are usually measured in man years. A commonly accepted benchmark sets the cost
for reviewing one gigabyte of data at well above $30,000.
In a typical enterprise
lawsuit, where adversaries are dumping hundreds of millions of documents on each other in
response to a discovery requests, the cost of analysis and review can easily reach tens of
millions.
As an example, during the acquisition of MCI by
Verizon, the two companies have deployed around 110
lawyers on each side for a period of 4 months in order to conduct a thorough privilege
and relevance review of electronic data.
Yet, the impeding costs are not the only problem. The e-Discovery process is also riddled
with human error – hardly surprising given that the process is characterized by an
extremely low distillation ratio, where only 5-10 percent of the data analyzed ends up
being relevant. A seminal study from a few years ago has found that legal researchers were
only 20% accurate in finding case relevant documents while being convinced they were 80%
accurate. A recent research showed human reviewers are consistently only 40%-50% accurate
in their data culling decisions, failing by both missing out on crucial data and by
including irrelevant documents. This typical low accuracy of human review reflects
inconsistent judgment, lack of coordination, and fatigue. Nonetheless, a failure in this
sensitive process can spell disaster, as was highlighted by two recent highly publicized
court rulings:
À
In one case Morgan Stanley lost a $1.45 billion verdict after a
À
In the second, a
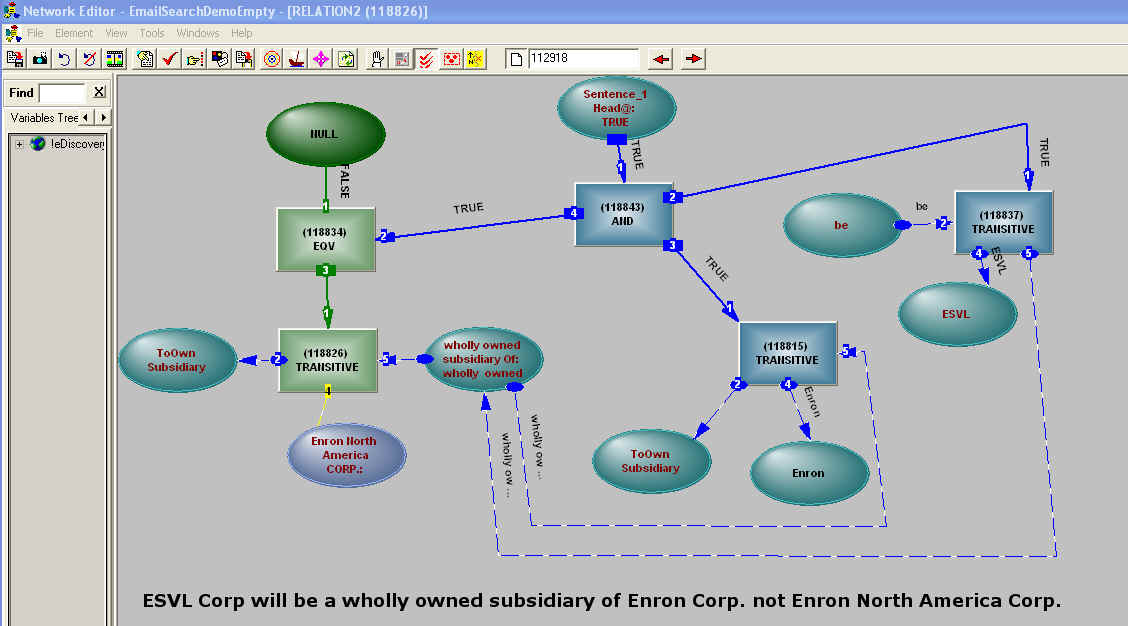
Caseopea has developed a both proven and groundbreaking text analysis platform that combines linguistics, semantics, logic and automated reasoning. The software both analyzes the text and learns from it. Context and consequence reasoning play an integral part in this dynamic analysis process. Text is progressively analyzed, so facts and concepts extracted during the analysis are being incorporated, on the run, into the contextual framework to be used for the next discourse or document, very much like the reader of this document uses previously gathered information to interpret this paragraph. This unique feature is especially crucial in the context of automatically reviewing email threads – where the narrative develops with each message and roles are frequently switched between parties.
Caseopea can put lawyers back on top of Legal Discovery.
Example
A query turned into structure.