Keywords: Contract management, automated reading, dynamic phasing, active structure, constraint reasoning, structural backtrack.
Abstract: A system for automated extraction of semantic structure from contracts in an EIS environment. The system extracts the definitions and builds the structure of the document as part of building the business processes and constraints described by the document. The system seamlessly combines objects and relations, logic, existence and time, and uses a holistic approach, in that thousands of small interacting processes contribute synergistically and opportunistically to the construction. Structural Constraint Reasoning is used at many levels in the process.
Enterprises whose operations are driven by contracts are poorly served by current EIS. The assumption of a "one size fits all" approach is not valid, as each contract is adapted in some way to the particular interaction between contractor and client, and there may be thousands of contracts in force at any one time, with thousands more being added or altered each year. There is strong interaction among the contracts, and yet no-one wants to read them, for there may be half a million pages of turgid text to wade through.
What happens is that people avoid looking at any contract in detail, and smear all the contracts in their heads, so they operate with a generalised contract. This serves well enough until a problem comes up. Given the choice between spending four or five hours to go through the particular contract in detail and be confident of what it says, or guessing, most people will guess, no matter how much the risk
Much simple text is handled using statistical methods, but the drafter of a contract is no respecter of statistics – most of the provisions in a contract are there specifically because the general provisions do not apply. Statistical methods are in essence no different to the smearing that people already do when faced with overwhelming amounts of tedious and boring detail – "most contracts don’t mention it, it so I will presume this one doesn’t mention it either". The purpose of the EIS for a contract-driven enterprise should be to save people from such mistakes, not build them in through crudity of methodology. Simple document searching will also not get very far, with "In no event shall" fifty words away from the business end of what should not happen, or "the matter referred to in Section 3.1(a)" not being useful if the search relies on word proximity.
Current methods, of extracting a few parameters from each contract, or allowing the user to search the mass of documents, offer very little support in managing issues and risks within the enterprise. An alternative approach, a system to machine read the contracts, allows the generation of structures which faithfully represent the meaning of each contract, allowing the meaningful querying of a single contract, automated tasks over a subset of contracts – where do the risks lie between main contractor and subcontractors on this project – or development of enterprise risk management over the portfolio of contracts. Such a system suffers from the need for reliability – either it works well, or it is useless. Current methods of text analysis are geared towards sentences of around twenty five words, rely heavily on statistics, and even then have a reliability of only about eighty percent on a single sentence, making them unsuitable for dense text covering business operations where large amounts of money change hands or the company’s survival is at stake, so it is clear that other methods must be found.
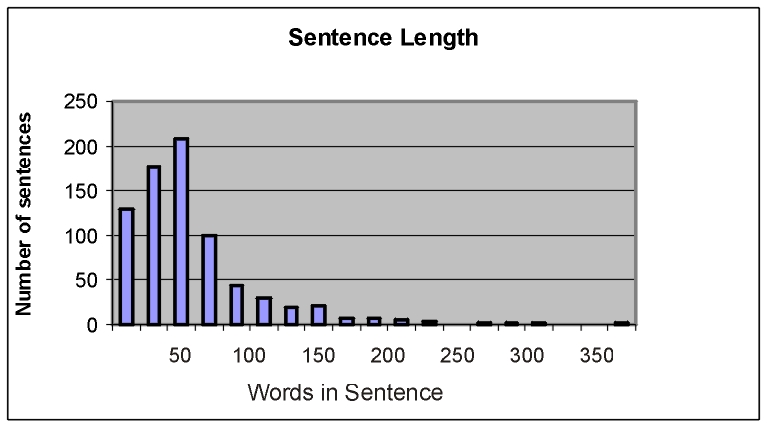
Figure 1 shows the size of sentences used in a typical contract of one hundred pages. There are about eight hundred sentences in total, with a large number of sentences around fifty words, but there are some around two hundred words, with a few up to four hundred words (many, but not all, of these long sentences use internal indexing, so they can be considered as a collection of smaller sentences).
Figure 1 - Sentence Size.
Taking into account possibly a hundred defined terms within the contract, and some terms may be defined counter-intuitively, simple methods that work for "The cat sat on the mat" are not relevant.
The language of contracts can seem like a centuries-old, rather arcane, programming language, except that the flexibility in what can be described is completely different to any programming language, and requires something that looks not at all like a procedural programming language to handle it. If we study the language in contracts, we see that
Objects are described and defined
Logic superficially similar to Boolean – "if...then..."- but if we look a little closer, the adversative, "the provisions of 3.1(a)", "wherever, however", "can, may, shall, must", we can see it is far richer and more detailed.
Existence, coming into existence and going out of existence is described in minute detail – "if any", "in full force and effect".
The ease of mixing logic, existence and time – "If it can be done before..."
The wide variety of relations – about fifteen hundred in typical contracts – their variety of interaction with objects and relations, and their modes of operation – ranging from the intransitive "to occur", to the symmetrical ditransitive "to lease", to the transclausal "to advise" (as in "he advised John that.....").
The seamless mixing of objects and relations – "the intention to lease the machine to make payment..."
The use of relation prototypes – "The Contractor may elect...... Such election carries with it...."
Complex set handling – "the provisions of Section 3, except for...", "including, without limitation, the costs (but not the fees)..."
The self-referential nature – "the matter described in Section 3(a)(ii)" or "the Estimates (hereinafter defined)" or "If the Contractor so advises the said vendor...".
One aspect that does come across strongly from legal language is its symmetry – truth and falsity, existence and non-existence, commencement and expiration, inclusion and exclusion. Procedural languages are asymmetric, but many logical languages also lack this deep level of symmetry. Contracts have one more characteristic that differentiates them from other forms of complex text, such as scientific – the need to describe potential human behavior – "It is the intention of the Client to invest in the Contractor under the....".
These attributes make legal language very powerful in describing complex business relations, but its complexity makes it hard to pin anything down to a small context, needed for simple searching, and it is almost as tedious to read as a large computer program, with its poorly marshalled definitions, its jumps all over the document, and its separate exhibits and appendices.
Flexibility aside, the legal programming language has the error rate typical of large programs built by several people without benefit of a compiler – defined terms that lack definitions, mismatched terms from external modules (the Exhibits), the cobbling together of bits and pieces from other contracts (the usual problems with reusable code), the same constant used in different places with different values, the glaring functional error because the user for whom it was written, and who alone understood the business aspects, would do anything, including take large risks, to avoid carefully reading what it says.
To make inroads into automated reading of contracts, we need to forego many of the current aspects of EIS. The languages and the methods of information storage are far too procedural or directed in nature, but the problem runs deeper. There have been many attempts to read text. Most problems that have been handled by computers so far can be decomposed into their elements without significant loss, which is what people are taught to do when faced with complex problems. Procedures are gathered together and linked – transfer money to account, update database. But harder problems are destroyed if decomposition or pipelining is attempted. The human apparatus that generates the text does not operate in the manner of simple stepwise analysis – it attempts, with a minimum outlay of energy, to generate a message that will be understood by another apparatus that operates in the same way – that is, capable of blending all aspects of its operation in a seamless whole – and has similar knowledge to the originator. As soon as one attempts to decompose the problem into parts of speech, grammar, semantics, failure is certain, because the information needed to understand the text becomes hidden or lost, and is no longer accessible to the apparatus at the time it is needed. It would be possible to recover from loss of information at one point if the message contained redundant information, but with dense, complex text, the points of information loss collide.
Let’s use an aircraft as an example. Any aircraft is a tight design, weight against lift and drag against thrust. To allow people to rush off and design the separate parts while oblivious of the whole would be futile. We don’t expect to see a jumbo jet with the fuselage consisting of an airport departure lounge, the tail of a Tiger Moth, and the wings of a MIG-29 – we expect a globally optimised system. Yet this has not been done in attempting to automatically read text. The people doing the tagging of parts of speech construct tagsets to suit their immediate purposes, with seemingly little thought of the following processes – not too many tags, because that makes them hard to remember and leads to argument over which tag is right, while information gushes through the cracks in the formalism. There is no attempt to analyse the information present in the text and see that it is preserved in the transformation – it clearly can’t be, so what exactly is the purpose of the transformation? The people doing the grammar accept the great loss of information handed to them, so further loss of information is not seen as a sin. The people turning the resulting parse structure into semantics never ask themselves why it is that so much is missing – how can it be that a person can understand this and we cannot. Just as in aeronautical engineering, where squandering drag or thrust or weight can exact a very heavy price, a very tight rein is required at each step to ensure that no information is lost. But we teach people about parts of speech and grammar – why is it not sufficient? We ignore all the other internal processes occurring simultaneously, and have no way to describe them, hoping instead that the mechanism we are training is sufficiently like ours that it will fill in all the gaps. For machines, we have to also fill in the gaps.
Even the notion of steps is not valid. An aircraft in operation is a system, with every part of it contributing continuously in some way to its operation. This is what we need to emulate. Words have meaning, and it is the meaning of the text that we desire. Conversion to parts of speech gives access to general rules like SVO (subject, verb, object) – and some general rules are essential when faced with tens of thousands of words. A general rule might cover a thousand words of a particular type, but some specialised words – less, as, that – may require a dozen rules each just for themselves, so there is tension between the usefulness of grammar, and what it hides in the process. For many words, we can’t accurately know the part of speech without knowing the meaning of the sentence, and yet we can’t know the meaning of the sentence without knowing the way the word is used. A quotation from the Pennsylvania Tree Bank project (Santorini, 1990) – "Be sure to apply these tests to the entire sentence containing the word that you are unsure of, not just the word in isolation, since the context is important in determining the part of speech of a word." So, conversion to parts of speech works well when it is easy to do, and can’t be relied on, certainly not as a single pathway, when it is difficult, as in the dense text of a contract. The Tree Bank tagset is itself very small, leading to large resulting ambiguity, so even transforming into this level of ambiguity is difficult. One could envisage cycling through all the possibilities of each tag with multiple alternatives – this might lead to a thousand alternative tag constructions in a long sentence, with multiple parses piled on top, or relying on some other means, not to determine the part of speech, but to already find the meaning, as the writer of the quote implies.
We are faced with two problems – we need a text analysis method which does not follow the well worn path of words, to parts of speech, to grammar, to semantics, and we need an underlying technology that has similar flexibility of representation as legal language. It should not be surprising that the text analysis method can be based on a system that does have adequate flexibility of representation. We will describe some of the analogues of aspects of legal language within the underlying system (the description is necessarily brief – if you are unfamiliar with the active structure paradigm, background is available in (Active Structure, 2006)).
The words of the sentence become invocations of dictionary entries (which means they are already inheriting the meanings of the words, as well as the part of speech), and are built into a parse chain. Some pruning occurs, due to interaction with neighbouring words (although this neighbour relationship may not survive rearrangement). Collocations that need more analysis than is available in the dictionary lookup are formed, and some meanings and meaningless lawyerly flourishes are coerced away. Several thousand logically controllable structures are used to assert grammatical relations. These structures may be static – a fixed number of connections, or they may be dynamic. Each connection may match to a specific object, or may have local conditioning. Each grammatical object may allow alternatives, so a participial phrase and a prepositional phrase are both alternatives of, and will match with, a prepositional chain component. Some connections demand a more specific match – a particular property (grammatical or semantic) must (or must not) be present as well. Figure 2 illustrates a typical rule.
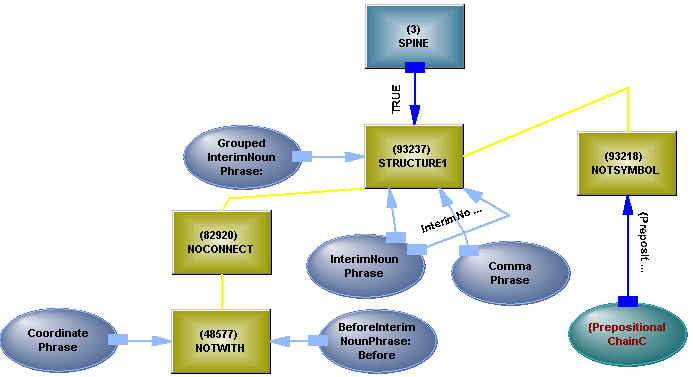
Figure 2 - Grammar Rule
The textual representation is
STRUCTURE1(GroupedInterimNounPhrase,{NOCONNECT(NOTWITH(CoordinatePhrase, BeforeInterimNounPhrase)), InterimNounPhrase, CommaPhrase, InterimNounPhrase, NOTSYMBOL({PrepositionalChainComponent1, Infinitive, CoordinatePhrase, RelativePronounPhrase})})
The structure has a logical control (SPINE), so it can be turned on and off, it uses a match connection that will not be connected when a copy is made (NOCONNECT), and within that connection, narrows the definition of what will match by controlling what alternatives can be present (NOTWITH). At the other end, NOTSYMBOL indicates symbols which would prevent matching (note the symmetry – things which will match, and things which won’t match). The textual representation may be ugly, but the use of a structure allows the system to modify the structure, or fabricate rules of its own. When a structure recognises a match, it typically builds a copy of itself, including its head, onto the grammatical structure, so a new object is now present, and that new object will seek new matches (searching is associative, so that only rules reachable from the object through a hierarchical network of alternatives are considered). Each new object begins with one property – a coordinate phrase, say, but by preceding a verb phrase, it may also acquire a property as a chain ender (plugged in by a different rule structure). This is a major departure from conventional constraint reasoning – instead of handing out meanings that apply only in 0.1% of cases and cause mayhem in general, such meanings are introduced by context (that 0.1% may sound low, but, with 40,000 words and 800 sentences and perhaps 2,000 clauses within the sentences, it means there may be one instance in every contract). Some structures reorganise the parse chain, stripping out a parenthetical phrase or an adverbial phrase as a modifier, and resetting the environment of the word tokens, so they can respond to new neighbours. There is no sense of words to POS to grammar phases here – the words are already semantic objects, even though many will have multiple alternatives as parts of speech, and multiple meanings. The process allows information from any source – POS, punctuation, grammar, semantics, count, previous sentences (through "said", "so", "same" and "such" and the invocations of words created by previous sentences) to interact in a synergistic and opportunistic fashion – a system comprising thousands of closely interacting elements cooperating to build a structure in small, potentially backtrackable, steps, rather than a sequence of operations with interfaces. There is actually a great deal of information coming from the text (we wouldn’t go so far as to say it is over-specified, but it is meant to be unambiguous to a knowledgeable reader), if it can all be used whenever it is appropriate to do so, and not in some predetermined and constricting order.
Relations are addressable as objects, and acquire most of their properties in a similar manner to conventional objects, by inheritance. This means that "to lease" is an object, but it also connects a lessor, a lessee and an object being leased, each of which also acquires properties by inheritance. In diagrammatic form (with ToLease as the object node of the relation)
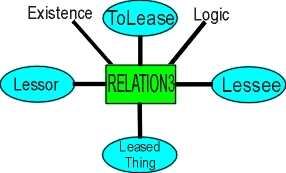
Figure 3: Relation as Object
Relations are prototypical for any part of speech – the same relation is built for operate, operation, operational, operationally, but some parameters may be unknown – "the operational requirements" causes an immediate construction of the ToOperate and ToRequire relations from the noun phrase (here is an operation that is invariant to the part of speech – it makes no sense to delay it until after the word to part of speech conversion, particularly when the relation(s) can begin to search for associations within the local context), but the subject is unknown at this stage (the relation may need to be merged with another relation built at some other point in the sentence, when it is realised they are the same relation). The subject, object, second object parameters can be objects, relations or clauses, depending on the particular relation. Immediate construction of relations which search for connections among accessible symbols provides an alternative pathway to grammar, in that the relation has far more knowledge than the grammar about what connections it can accept – particularly cross-correlations among the parameters, or certain prepositions that are stereotypical of the relation ("...sued for damages..."). We call this the "semantic octopus" – the relation actively seeking out suitable objects in the local context. Clausal relations – "he was convinced that..." – support a clause below them; they provide the same kind of logical and existential support to the clause that the discourse structure provides to the sentence.
The logical and existential connections allow the relation to be controlled. Logical connectives do not differentiate between logical and existential connections (the difference between "he shall..." and "he can..." is that the sentence assertion coming from the discourse structure connects either to the logical or existential connection of the relation). Nonexistence - "cannot" - is obtained by placing a NOT operator in the existence connection, the operator inverting the logical values flowing in its connections. Bayesian values may be present in either of the logical or existential connections – the relation operator maintains consistency, so that at any time, the logical value cannot be greater than the existential value ("he shall" is inconsistent with "he cannot" over the same timeframe). The time properties of the specific relation, if they exist, are held in attributes of the relation – the relation may inherit a generic duration (typically a range, if the relation is not instantaneous), or it may be specified, or calculated from connected relations. The time properties are diffuse through the structure, and diffuse operators are used to search the surrounds to find the start date, etc. (another radical departure from conventional constraint reasoning).
For a fragment like
The Contractor may elect to exercise the option to extend the Contract...
Figure 4 shows how the relations are connected to form layers to any depth, with logical, existential and time control on each layer.
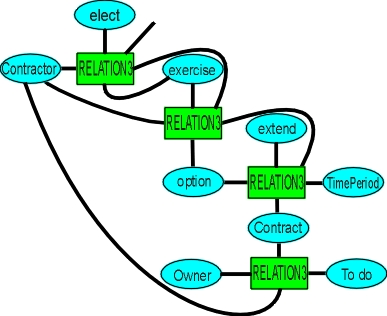
Figure 4: Option to Extend.
A contract has many references within it to other parts of its structure. There are two important structures in a contract – the structure of the document, with all its cross-links, and the structure of the business arrangement it describes. Both of these structures need faithful representation if the built structure is to stand in place of the textual contract. Both structures are built as the contract is read. Some references are to places ahead in the text – these are created when the reference is read and checked later. A reference in Section 3 to Section 13 has to be able to capture everything that is Section 13 – the sentence structure, the objects and relations, the logic, and allow all these things to be accessed from the point of reference.
Large contracts (more than twenty pages) have many definitions, which are often gathered together at the start of the document, and may even be ordered alphabetically, to assist the reader. But definitions typically rely on other definitions, which do not respect alphabetical order. If A is defined in terms of Z, and Z is defined in terms of K, then the definition of K must be known before reading Z and then A, otherwise meaning will be distorted or lost. For a person reading definitions in alphabetical order, the person needs to leave the definitions open, and only close them when all are known, something quite difficult to do over a dozen pages and a hundred definitions. The system determines the necessary order by scanning the document, arranging formal definitions ("Force Majeure" shall mean...") in read order, reading informal definitions ("...the site ("Site")...") inline, and flagging seemingly defined terms that are undefined.
A major difficulty with reading long, involved sentences is that nothing happens in a predictable order. The order of resolution comes from the words, their meanings, and the way they are arranged. It can’t be known which parts of the sentence will resolve first, so it is attacked in a broadside manner. Resolution typically proceeds from the ends, or from virtual ends in the sentence – "...;provided, however...". This broadsiding introduces difficulties, as the early part of the sentence may establish context for a later part. In particular, a definition of a term may be given, which is then used later in the same sentence, or there are references within an embedded index structure which assume knowledge of structures in previous index statements – "(iii) as mentioned in (i) above....". This new context, or the removal of a parenthetical phase, may require restructuring of the parse chain – when a definition is found, the rest of the sentence must be searched for its (possible multiple) use, and the word tokens changed appropriately (otherwise the definition would be incorrect – it is important to note that the built structure is meant to be a precise model of the meaning, not an aid to searching). In operation, a grammar rule may need to be suspended, because some other part of the structure being built on the chain is under construction, or matching is blocked by a symbol that will later disappear. Not all the grammar rules are static, some having virtual "wheels" which allow them to run along the parse chain, searching for objects which may either be a long way away, or not exist. These mobile rules carry sets of objects which, if detected, will cause suspension or failure. If suspension or failure, then the rule requires reactivation when the cause is removed (the parse chain is restructured), or goes out of scope (the offending symbol gets buried). The need for dynamic phasing is handled by throwing connections – activity on the other end of the connection will cause the connection to be swallowed up and the rule to restart matching, unless that point in the structure has been buried by the actions of other rules in the meantime. Automatic handling of dynamic phasing is one of the essential features of a reading system for complex text – a requirement that can be ignored if the text is simple enough.
The semantic structure is being built in parallel with the grammar structure, so there is no concept of separate phases – when the grammatical analysis is complete, so is the semantic structure. Semantic knowledge is used at every step – a collocation may depend on the semantic properties of the different words, a decision where to separate several nouns may require analysis of which ones group or have a relation, which do not. The final step in construction of the sentence is a semantic one – the logical and existential connections of the primary relations of the sentence are connected into the discourse structure. There may be other steps required after the contract is fully read – statements such as "all other amounts expressly deductible in this Agreement" requiring evaluation on completion of the entire structure (the equivalent of a link phase in a compiler, except here the structure is being searched according to instructions given in the text).
The description sounds like a bottom-up approach to the text analysis problem, but that would require a huge number of rules for long sentences, where a relevant symbol may be fifty symbols away. Outlining is also used, in that possible switching points in the parse structure – coordinate phrases, relative pronoun phrases, open verb phrases (no apparent subject) – are found, so that a notion of an overall structure is also available as analysis proceeds. If there is no possible following clause structure, a coordinate conjunction can only be for grouping.
The system has to know enough about the area of the contract so it can group things appropriately – money goes with money, war goes with storm (both are "perils"), equipment goes with fixtures, termination goes with expiration, working capital is a business component. The system has an ontology, but it looks as much like a conventional ontology as an airport departure lounge looks like an aircraft fuselage – the ontology is optimised as part of a system. The ontology will be referenced millions of times during the course of reading a contract, so it needs to be fast, it needs to be compact, it needs to be controllable from below (the object should be able to control which properties it acquires – a right to do something has many of the properties of a person, but is not a natural person), it needs to be dynamically extensible, and that extensibility needs to be backtrackable. The ontology includes words, both as parts of speech and as objects or relations, with relation parameters having inheritance in the same structure. The ontology, and the dictionary, are made out of the same elements as the relations and the logic, and so are as backtrackable as every other part (why is it necessary for the dictionary? – we may be backtracking on a sentence which adds a new term to the local dictionary). The ontology also supports operations on it – similarity, consistency and not_inconsistency of objects. Without this dense knowledge and complex function, the resolution of long prepositional chains (so beloved of lawyers) would have no basis other than proximity, and would be wrong about half the time. To give some idea of the extent of knowledge, a system to read management contracts may need 120,000 elements, split between a hundred pages of grammar (the grammar is maintained in textual form, although the text is just an instantaneous representation of the grammar structure, no compiling occurs) and the semantic structure (both the inheritance hierarchy and about fifteen hundred relations are maintained with graphical tools, but again, one is viewing a representation of the structure). The resulting contract structure, for a fifty page contract read in several hours, is about half a million structure elements, in 100 MB of memory (grammatical structure is continually salvaged, and the memory image of the active structure is stored in a compressed form on disk, and can be reloaded in a few seconds for querying or analysis).
Prepositions are divided into two classes – general prepositions, like "during" and "of", and relation-specific prepositions – the "for" in "he sued for damages". Maps are provided for both. A general preposition has multiple meanings, and the system has to cycle through these meanings, comparing each map to local context using constraint reasoning to find the right one, so relation-specific prepositional maps (which are still checked for applicability, and may just be a path to a general map) can save considerable time and keep the number of general meanings manageable. Each map contains detection structure – is the right hand parameter a child of person and not of lessor. If the detection structure matches, the build structure is created, which may involve building attributes or relations or object groups ("Jack and Jill" is an object group, radiating the properties of the group and its members, as are the verbs in "he created, managed and operated"), or involve rewiring of existing structure (the structure may be built in any order – a programmer’s nightmare).
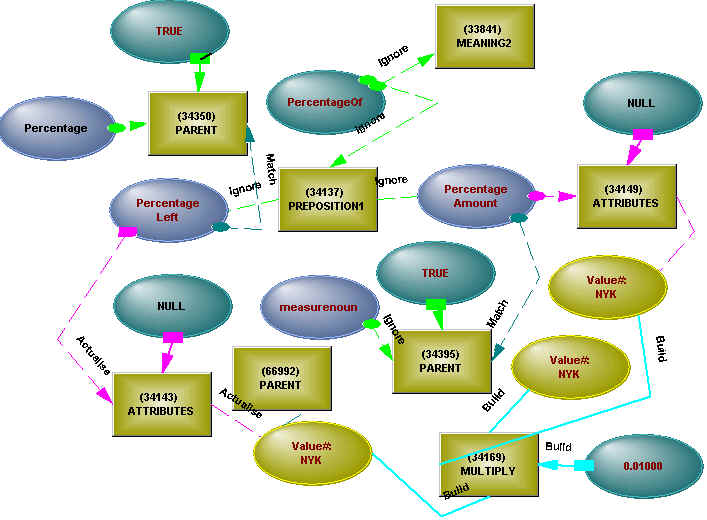
Figure 5 - Percentage Map
The prepositional map has connections that match to the existing structure but are not built, connections that actualise into the structure (that is, check for and then actualise inheritance), or which build new structure. The particular map shown in Figure 5 combines objects with numbers, and includes numeric operators which perform calculations (the MULTIPLY) when values flow through the structure.
Sometimes, several readings of a sentence are possible. This word could be a noun and that a verb, or vice versa, or groupings could be different (the "John spoke to Jack and Jill and Fred went home" problem). With long sentences, there can be many of these points of ambiguity, and no amount of rules will avoid the necessity to "suck it and see" – the inconsistencies will only become apparent when an attempt is made to put the objects together. The system has structural backtracking, so it can set an object to be a particular thing, and observe the result (that is, see if the structure builds to completion, including the semantic structure, connection to objects in previous sentences, all the structural change that happens along the way), then undo all that and try something else. Sometimes it still cannot resolve the alternatives, so has to build them and seek resolution later.
A system for extracting structure from contracts has been briefly described. It uses a systems approach to optimise all of its components for a global purpose, and make available all of its knowledge all at once. The automatic reading of contract text reduces the errors in a portfolio of contracts, reduces the likelihood of guessing on the part of those charged with administering or operating the contracts, and allows operations across a portfolio that would otherwise be impossible (people could do them, but would give up or refuse). The system can be used to support enterprises that are driven by contracts.
References
Santorini, B., 1990. Part-of-speech Tagging Guidelines for the Penn Treebank Project