Using Knowledge Fusion to Automate the Extraction, Transformation,
and Loading of Data into Data Warehouses
A Tupai White Paper
Executive Summary. Data preparation is usually the most expensive and demanding
phase in data mining projects, often accounting for up to 85 percent of the overall costs
of such projects. Data mining tools rely heavily on the quality of the data that they
analyze. This is particularly true for "learning" tools such as Neural Networks.
Because these tools rely on a good selection of training samples, noisy data can render
useless most existing systems and tools their output useless. This white paper describes
the use of knowledge fusion technology to set up an automated production environment for
data preparation.
Stages of a data-mining project. It is common practice to divide the data preparation process into three interdependent activities: Data Extraction, Data Transformation and Data Load. Data Extraction involves gathering data from operational databases, legacy systems and sometimes possibly external sources such as third party research data. Data Transformation refers to the process of transforming, validating and filtering the collected data, to ensure that the data to be stored is consistent, reliable and contains the right level of details to support the data analysis activities. Finally, Data Loading refers to the loading of the processed data into data warehouses, data marts or other isolated data retrieval systems. The prime objective of these storage systems is to support massive, concurrent and efficient retrieval of data for analytical purposes.
The Challenge of Integrating Knowledge from Different Areas of the Organization
Above and beyond the technical complexities of aggregating data from different sources, integrating knowledge across the enterprise is challenging because of the different focus and orientation of each constituency. Creating a coherent, consistent body of knowledge from data collected by multiple divisions and functional areas is one of the most complicated processes in the IT industry, requiring coordination of a number of complex processes:
Different levels of detail. Because of the different orientation, similar data may be stored at different levels of aggregation (e.g. by zip code in one place and by state in another). Missing data (also called "nulls"). Data found in the company’s databases is often incomplete. The missing data fields, randomly scattered, introduces a significant level of noise, which can plague the data mining process. There are a number of options to dealing with missing data, ranging from rejecting incomplete records to using special rules and logic to transform nulls into usable values without introducing errors. Inconsistent data. It is not uncommon to get conflicting information from different sources. Resolving these conflicts is part of the data cleaning process. Inconsistent coding systems. Different systems may use different codes and/or different data storage formats to represent the same information. As part of the transformation, all codes need to be translated to a uniform convention. Here again, the mapping could be as trivial as a lookup table or it could be a complex relation. Time-sensitive information. Over time, companies may change certain aspects of their data capture and codification. Identifying calendar events and taking them into consideration in the transformation/cleaning process may be of crucial importance in interpreting the data. Another time-related issue is that of seasonality. When reviewing time-dependent information, time-series analysis should be used to assist in the detection of errors and the substitution of missing data fields. Aggregation and Classification. The analysis process will often require the aggregation of data into new categories. The category "soft drinks", for example, may need to be applied to products of different brands and packaging. The mapping can range from the trivial ("if Coca-Cola then soft drink") to the complex ("if product is a drink and bottle size was small and purchaser bought other items categorized as health foods… then drink is a Special Health Drink"). Notice that in the complex example we used correlated information and ad hoc analysis of buyers’ purchasing habits to help classify health drinks. Preserving the Data Schema. Operational databases will typically hold information in hundreds of interrelated tables. These databases will nearly always have a "data schema", or a set of instructions and definitions that is used to ensure data validity and integrity. Unfortunately, much of the knowledge captured by the data schema is lost in the data warehousing process. An intelligent transformation system should exploit the information embedded in the data schema and utilize it in the data ETL process.
Data Transformation and Data Mining are Inherently Intertwined.
We mentioned already that good data transformation is essential for effective data mining. The converse is also true – data mining can play an important role in the data transformation process by providing context for the transformation process. In the same way that human translators need to see a word within the context in which it is used, so it is with data translators. Data mining techniques with rapid turnaround can provide this sense of context to the data transformation process. It is therefore only natural that Tupai’s Knowledge Fusion should be used in just that manner.
Creating a Production Environment for Data Transformation; A Two-Phased Approach.
As we mentioned in the previous paragraph, having a context for the data to be transformed facilitates the transformation process. In implementing the production environment, we recommend a two-phased approach.
The first analyzes samples of the data to build knowledge and develop context. We call this phase "the learning phase". The second phase does the actual "heavy lifting" of generating the data transformation and loading it into the warehouse.
The Learning phase. During this phase, the data fusion tool connects to the various data sources and reads sample data sets from each. The reading of samples is synchronized via dynamic logical controls incorporated into the tool’s operation. The knowledge generated during this phase is captured by the tool's active model.The active model is a dynamic and flexible environment where knowledge is captured and combined to create a powerful data transformation system. The active model can include various types of knowledge, both self-mined and user-specified. These include data distributions, correlations among data elements, business rules, data conversion rules, data schema and other types of constraints and relations.
The active model uses sophisticated statistical software processors to accumulate stochastic knowledge about the variables in the database and to build internal probability maps, for detecting relationships among these data elements. In addition to performing this kind of analysis on data elements appearing in the database, the statistical processors can compute similar distributions and relationships for complex mathematical and logical expressions that can be defined by the user and can be based on multiple data fields from different data sources. These extensions to the data model serve a crucial role in the second phase.
Upon completion of the learning phase, analysts can review the multi-dimensional relations and search for invalid clusters (combinations of parameters which should not appear together). They can then remove these relationships, thereby guaranteeing that these combinations will be flagged as invalid in the cleaning phase. Alternatively they can attach special "pattern sensors" to the combinations. These sensors will trigger, upon detection, specific logic that is required to handle the data during the cleaning phase.
The Learning phase can be followed by an optional review and adjustment session. In this session, exceptions (warnings) that are detected by sensors or inconsistencies that are flagged by the system are routed to a data analyst. Based on the analyst’s responses to these error conditions, the system updates and adjusts its internal probability maps, thereby acquiring new "expert" knowledge for guiding the transformation process.
The Data Transformation Phase. The Data Transformation is where the real work takes place. Using the relations, probability maps, and rules that were constructed during the learning phase, incorrect data is corrected, incomplete data is enhanced, and codes are translated and unified. Steps in the "assembly line":
Completing missing fields. As it passes through the assembly line, missing fields are detected and the system evaluates what is the most probable value to be assigned to the field. If more then one field is missing, the same relations and logic used to assign the first null will constrain appropriately the values used for the next null so values are consistent within records. Error Detection. The same mechanisms that were used for completing missing fields are used for error detection as well . This is done by flagging values which either conflict with an explicit business rule or show up on the distributions as having a very low likelihood of being correct. Linking Domains. The context provided by the probability maps also serve as a good guide for matching disparate records and mapping information from one domain to another. Analyzing Time-Related Fields. A knowledge model that augments the probabilistic model with a time series analysis tool will provide powerful filtering capabilities for time related fields. By utilizing projections, such a tool can fix and filter out noise in time sensitive data. With the introduction of calendars and specific time events, the transformation model is extended to an unprecedented level of reliability and realism.
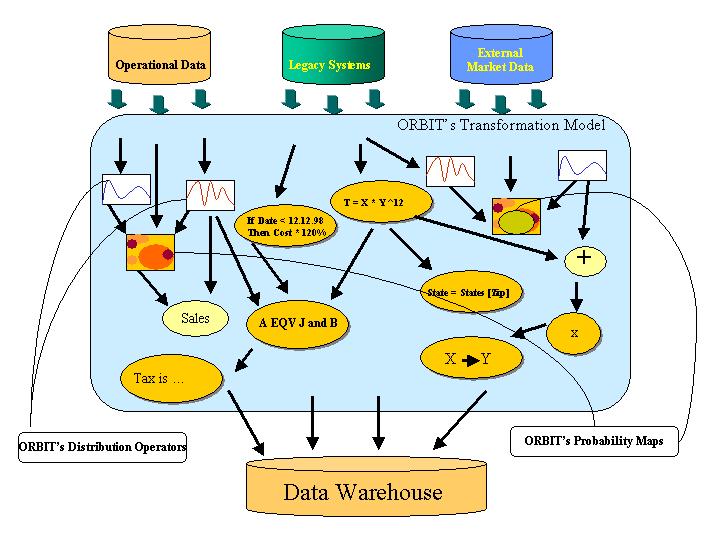
A Production Environment Built using eCognition
The diagram illustrates a production environment built using eCognition as the transformation engine. The active model incorporates and integrates various types of rules and knowledge inferences. The stochastic operators that were constructed in the learning phase take an active part in the transformation process, providing valuable knowledge of context. In addition to automating the transformation process, the use of stochastic operators that are derived from data sampling provides administrative efficiencies as well since it eliminates the need to manage and maintain a large number of transformation rules.
Deploying the Production Environment for Ongoing Data Mining Activities
The benefits of establishing contextual knowledge in the production environment continue well after the data warehouse is complete. With a robust context engine at their disposal, data mining operations can discover relationships that may have eluded detection otherwise. The same operators that provided context for the transformation now assist in enhancing the explanatory value of the data. Because the transformation engine is a dynamic and flexible model, it can be easily adjusted and updated to incorporate new knowledge and new data sources. Tupai’s Knowledge Fusion production environment is scalable and distributive so the whole process can be distributed across the organization with multiple models cooperating in a distributed fashion to ensure consistency across widely disparate parts of the enterprise
Conclusion
Establishing a production environment for the construction of data warehouses
accelerates and simplifies the process dramatically, while enhancing accuracy and control.
Moreover, this infrastructure continues to serve the data mining operation after the data
warehouse is complete. Tupai’s eCognition technology provides a unique system for
creating such a production environment. eCognition extracts knowledge from databases while
integrating implicit, stochastic and explicit knowledge into a unified, coherent and
active knowledge model, useful for both analysis and operationally.