A Pipeline to Failure in Bioinformatics
Introduction
Many of the NLP papers to do with medical bioinformatics claim accuracies of 70 or 80%. They describe a process where information is pipelined through several modules, each having poor reliability, and in combination an unacceptable reliability. Let’s assume the purpose is to do with patient health, and a reliability of 99% is desired. What should we learn from this, other than the approach these papers describe is inappropriate for the purpose. If we are to achieve high reliability, then the whole concept of modularization needs to be eliminated from our thinking.
Complex problems are routinely reduced to their components for solution – we make the pieces and assemble them together to build airplanes, cars, electronics, with very high reliability. Modularisation works well when the problem reduces easily, and when there can be clean interfaces between the modules. Then each module can optimize its structure to suit the task, only passing across the interface what is required for another phase ("another" does not necessarily mean "next"). It was only when people realized they could separate propulsion and lift, rather than leave them so beautifully integrated in a bird’s wing, that successful aircraft were built. Let's take this analogy a little further. People separated the functions of thrust and lift, but they did not separate them in time. Imagine an airplane that had a thrust phase where it shot straight up, and a lift/glide phase, so thrust and lift are sequential processes. It would be extremely unreliable at arriving at a specific destination (ICBMs can do this, but they arrive at their destination nearly vertical at supersonic speed, so you may not care to land in one, and it is estimated that if deployed, they would be about 70% reliable. Something else also does this, but its reliability is too painful to discuss. A gun has thrust and glide phases, but it helps if you can see what you are aiming at - with language, you don't, or not exactly. The bird and the plane make continuous small adjustments, the bullet doesn't). No-one would suggest time separation of thrust and lift for commercial aircraft, so why do we automatically suggest it for grammar and semantics. There seem to be two reasons - the grammar of language has been studied for a long time (hundreds of years), so we assume it works, and we still have only the crudest formalism of the concepts that natural language manipulates, because we again insist on reduction to some single simplistic form. The reality is that neither grammar nor semantics works particularly well in isolation or in a strangled form.
Some problems can be readily reduced to their components, like a car or plane, but cannot be reduced at all, if reduction means separate processes in sequence. But a computer can drive a flight simulator - yes, by doing little bits of every process involved in sequence so none gets out of phase with the others, which is exactly what we will be arguing.

The directionality of process modularization is both its strength for moderately complex problems (making phasing external to each process) and its weakness for very complex problems (its destruction of the nature of the problem), whereas integration and undirectedness force no assumptions on the form of the problem, and allow the focus of activity to switch wherever the problem takes it.
There are many other areas where modularization leads to poor outcomes – anywhere where the effects of many influences need to be taken into account throughout the process – but NLP is one of a few where the results are already demonstrably poor after a few seconds of processing.
Why does modularization not work with bioinformatics? Because we are dealing with a cognitive mechanism that operates in a massively parallel mode, with all the information available to all of the parts simultaneously. We throw information away when we attempt to reduce the problem to a sequence, and cannot recover it. The information we are dealing with is deliberately "just enough and no more" for another human who is well versed in the context in which the message is being read, so we need to emulate some of the properties of human cognitive apparatus if we are to extract information reliably.
Let’s say we want to turn words into POS (part of speech) tokens. We take each word and perhaps its near neighbors, come up with a part of speech with perhaps a few flavors (adjectives - JJ, JJR, JJS). In general, it works reasonably – we may be able to claim 97% accuracy. But if we want to achieve 99% over the entire system, this is nowhere near good enough. So what went wrong? The algorithm we created to determine the POS tokens made decisions in an information-poor environment, it made them prematurely, the algorithm could not change to reflect what it had already read of the discourse, and the conversion was into an information-poor formalism that did not support the grammar or semantics to be built on top of them.
Some words can be turned into POS tokens with complete accuracy – "the" for example. But many words can’t – a large number of words can be nouns or verbs, words can be past tense verbs or participials, some words can be either prepositions or subordinate conjunctions (Treebank assumes away the distinction). The near neighbor words are not an infallible guide, as rearrangement may result in completely new neighbors for a particular word. Nothing said here is new – here is a sentence from [3] - Penn Treebank
Be sure to apply these tests to the entire sentence containing the word that you are unsure of, not just the word in isolation, since the context is important in determining the part of speech of a word.
This statement says quite clearly that converting words to POS in isolation and then parsing the tokens is not going to work. You need to know the sense of the sentence, before you can know for sure how the words in it are being used. To save the modularization concept, people immediately set to work to bypass or ignore this requirement. It should have been obvious that poor reliability would follow. The whole notion is flawed - Treebank uses approximately forty tags. The purpose of Treebank was to tag text - it was not to provide a basis for grammatical or semantic analysis. We are using a component in the NLP process that was never intended to be used in this way - should we be surprised when the combination fails so badly?
The Medpost [1] paper is often cited for claiming 97% accuracy of POS tagging. It uses hidden Markov models (HMMs) associated with each word to determine parts of speech. Let’s take a moment to see how it performs. The 97% accuracy is for sentences with an average length of twenty-five words. If sentences are short enough, then they cannot have nested or jumping prepositional chains, or relative pronoun clauses or subordinate clauses or other causes of error - they will mostly be of the linear form "The cat sat on the mat". The error statistics are not flattering for subordinate conjunctions (10/120) or past tenses of verbs (64/306), or the handling of quotes (are they really mismatched in the source?). It should be obvious that longer sentences will be deleterious to the error rate. But why should this be so, when the longer sentence provides more context, rather than less, making correct determination on POS more likely? The HMMs are poor at handling discontinuity. They assume that proximity implies relevance. Text is discontinuous, and the longer a sentence becomes, the more likely it is to have discontinuities within it. To illustrate, a simple well-behaved sentence looks like a string of beads.

The proximity concept on which the HMM relies is not invalidated by discontinuous structures within the sentence.
A sentence with a prepositional chain:
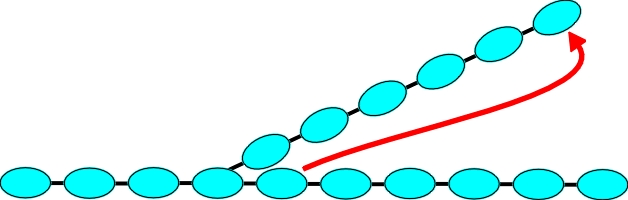
The word is checking on a neighbor that is far from it in the structure and in relevance, but close to it in the text. Proximity is a very poor guide to relevance in the presence of prepositions (and for most prepositions, we are quite sure that is what they are). Prepositional chains have their own grammar - they "sheathe", so a jump hides everything over which it jumps, and changes the neighbor in the process.
A sentence with relative pronoun clause ("the house that Jack built burnt down").
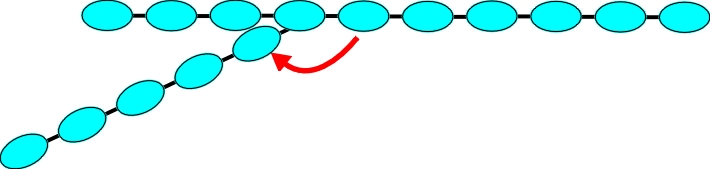
The relative pronoun causes a cutting and folding back that linear text conceals, so what is a system to make of "built burn" without knowing of discontinuities.
A more complicated sentence

This sentence still only has twenty-five words, but has many sites of potential error for a system using proximity to determine parts of speech.
We are in the position that we can have an unacceptable accuracy in one module (97%) if we have short, simple sentences that do not confound the assumption that proximity signifies relevance. Actually it is much worse, in that the low information content and smearing of the POS tags in the output guarantees poor reliability in the next stage, and the claim of 97% needs to be seen in this light.
Need it be as bad as this? The MedPost paper cites a tutorial on HMMs [2]. In it are these wise words
Syntactic Analysis.....Finally there are tasks for which the grammar is a dominant factor and....it greatly improves recognition performance.
Semantic Analysis... This again serves to make the recognition task easier and leads to higher performance of the system.
In other words, don’t use HMMs alone where there is more information available. If we already have semantic information, start using it immediately. To be more precise, do not use a statistical device which smears information that later stages are attempting to retrieve. To use a parser after an HMM which is antithetical in its operation (the parser is looking for jumps, the HMM assumes there are no jumps) means we have greatly increased the potential for error. An HMM may be of benefit in spoken speech, which does not have the discontinuities of text (the listener would be too confused, although a similar effect is achieved across separate utterances – the discourse), but the fact that we even consider pipelining two such antagonistic elements in textual analysis shows there is considerable room for improvement in reliability.
It is not possible to reliably convert words into parts of speech without knowing the grammar of the sentence (more exactly the discourse), and it is not possible to reliably know the grammar without knowing the semantics. But we can’t know the semantics without knowing what the words mean. A circular problem, so what to do? A good rule is to immediately do what is reliably known, and leave an unreliable conversion until more is known around it. Some words – "the", "relationship", "of" - are unequivocal – they already have singleton POS. We will be left with many words having alternative parts of speech to take forward, so we will need to be able to handle that. We can prune some of the alternatives using longer range patterns, with the proviso that some pruning may need to be undone if the structure the pattern identified changes due to rearrangement. The result is that at the exit of the POS stage, we have 100% reliability, because the valid POS is still expressed in the output, and we will repeatedly come back to the POS stage as other processes progress.
We are now beginning parsing with alternatives in the tokens – won’t this be a problem? The use of single values of POS would already have destroyed the goal of reliability, so no, it is not a problem, it is part of the solution. As the parsing proceeds, we build structure on top of the tokens, with semantic structure-building proceeding in parallel with parsing – not because we can, but because it is necessary to support parsing and POS tagging. Sometimes, parsing will recognize a structure which needs to be rearranged – a prepositional chain, say, between verb auxiliary and verb:
You shall, under the circumstances, report to the registrar.
The "under the circumstances" chain is cut out and will later be used as a modifier for the "report" relation. The cut is cleaned (any structure based on what was previously assumed is destroyed) and repaired, and "shall" and "report" each find themselves with a new neighbor, and "report" is now quite sure what POS it is. (What is being described here is a dynamicity of the parse chain lacking in the pipelined equivalent, but essential for integration of the processes in parallel.)
Further problems ensue if the POS formalization is poverty-stricken. Verbs, for example, can be intransitive, transitive, ditransitive, causative, clausal. If the only representation for a past tense verb is VBD (Penn Treebank), which also covers participials, there is little chance of extracting any worthwhile meaning from the resulting stream of tokens.
By using POS tokens that are far too general, we are introducing ambiguity from which we will not be able to recover, rather than eliminating it. Here is but one example from Medpost:
upon: (a) physical performance; or (b) quality of life; or (c) morbidity/mortality.
upon_II :_: (_( a_NN )_) physical_JJ performance_NN ;_: or_CC (_( b_NN )_) quality_NN of_II life_NN ;_: or_CC (_( c_NN )_) morbidity_NN /_SYM mortality_NN
The information about the structure ".... : (a)........; or (b).............; or (c)................." is destroyed, the "a" turning into a noun, the semicolon turning into a colon (more exactly, an object which includes dashes, colons, semicolons), and the notion of a higher level structure is completely lost. An alternative tagging approach would present the parser with neighboring parts of speech obtained through the high level structure - that is, for "...upon : (a) physical performance; or (b) quality of life;", the left neighbor of "quality of life" is "upon". Consider how much effort would be required downstream of POS tagging to recover this, if possible at all. In this light, the claim of 97% reliability seems rather pedestrian.
Let's go to extremes for a moment. If we have a one tag set, simply "Word", then we will have 100% tagging accuracy under all circumstances, and zero information from it. If we use a twenty thousand word vocabulary as a tagset, we know what each word is, and have almost zero information without generalizing across words (a "grammar"). Some analysis to show that a tagset of a certain size would be appropriate for some complexity of language would be worthwhile - at present the size of the tagset is geared to what a person can remember, without there being too many arguments between taggers over the appropriate tag. As soon as we bring in the necessity that the tagset must not lose any information for any following stage, the whole notion falls to pieces.
One interesting aspect of most tagsets is that they are usually treated as separate objects, without inheritance. A noun is a noun is a noun, so grammar rules for nouns (NN) should also cover proper nouns and plural nouns. There is merit in keeping the tagset small, but we want to be able to generalize to the maximum, so sometimes we need to know the verb is ditransitive to understand the structure of what follows it. With current practice, we either know a POS tag with little information, or we know the actual word. There is a spectrum to be filled here, either by specialized tags in a family, or attributes attached to tags (properties) that may be accessed by grammatical patterns (we admit to using both approaches).
There is an insistent theme here, of throwing away useful information to reduce the diversity of the symbols being handled. This is not the way to achieve high reliability. The need for simplistic generalization to a small number of symbols existed before computers came along, but is no longer necessary. The small number was necessary to permit verbalization of the grammatical rules for a natural language, but the listener already knew that the rules would be more honored in the breach than in the observance. That is, the rules have many exceptions that need to be handled efficiently, and which the grammarian understandably did not address in a grammar built by hand, but which do need to be addressed if we are to achieve high reliability from a machine.
By not allowing alternative POS, we are destroying information by making decisions too early with inadequate information. Taggers which produce alternatives will usually have misleading statistics attached to the alternatives, and for the same reason – they can’t see enough of the context or are unaware of discontinuities in it. Information is precisely of value because of its unexpectedness - each time the system defaults to the most probable form without analysis, it is destroying information.
We are starting to differentiate between current practice in bioinformatics NPL and a system which values the information it is given, which operates in a quasi-parallel, opportunistic, synergistic fashion, with no distinction (and no interface) between conversion of words to parts of speech, parsing, building of semantic structure, and which treats the dichotomies of truth and falsity, existence and nonexistence, inclusion and exclusion, creation and destruction of objects and connections, with equal facility. Running on a computer, it cannot have the massive parallelism of human cognitive apparatus, but if each step is suitably atomic, and the result of each step is immediately broadcast to every other entity that may be interested in the outcome, and these other entities can intervene, then it can appear to be handling a complex problem in parallel, and lay claim to some similarity of outcome.
Instead of poor choices inside different modules ("we wanted to limit the number of tags" - this is as scientifically relevant as "we only put one wing on the plane, to save money", and someone else can tolerate the unreliability, or you keep the plane on the ground), the optimisation becomes system-wide, so information is represented in the most appropriate way, and is still accessible by any other part of the system. The problem is attacked in its entirety, in other words, rather than there being many localized a priori decisions which have a disastrous effect on overall system performance. To return to the aircraft analogy, if the aircraft fuselage was designed ignoring the fact it has to be lightweight, have a low drag factor and carry wings and a tail, the optimum design would be the airport departure lounge. Only when the total problem constraints are taken into account, can a valid design emerge. All the pieces affect each other. That means the whole problem has to be handled by the same technology, which means all the piecemeal local designs in a pipeline approach have to go in the dumpster. They may be valuable for some other purpose, just not for deriving meaning from text.
A visualization of the non-modularized system might look like:
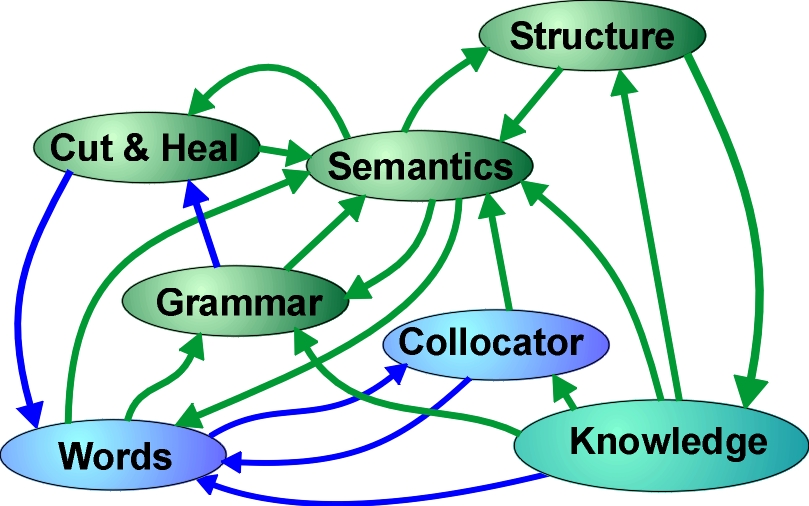
This diagram gives some indication of the many operations proceeding in parallel. While there is a constant drift from words to knowledge, there is also a constant rearrangement and interleaving - the words immediately inherit POS and semantics, the grammar uses semantics from the outset, the grammar rearranges the words, modifies their inheritance, deletes some words, inserts others that are elided in ordinary text, a collocation appears and subsumes part of the structure. Prepositional chains may build relations, or clausal relations may, or sometimes they share building of the same relation. Preceding sentences in the discourse have created semantic structure, which informs the new sentence being constructed. This may all sound very complicated to someone who is used to pipelining of processes, but as the structure phases itself, it is actually easier to handle the vagaries of text this way. Each small piece can be treated as though it is independent, whereas in operation it is wrapped within all the other pieces, the connections among the pieces determining the phasing.
The system requires a structure that is active and extensible, is self-modifying and undirected as to purpose. We won’t dwell on any particular version of such a structure, except to ensure the reader that such active structures exist, and point out the obvious (and seemingly well advertised) problems such a structure avoids.
We have skipped over the issue of semantic structure, but the same approach, of making single value decisions at the wrong time and using formalisms that destroy information, seems just as prevalent there. See A Semantic Octopus for using meaning to guide making connections in parallel with grammar, and Relation Structures for a formalism that does not throw away information about relations.
Conclusion
The desire to solve a difficult problem using a simple formalism, which has shown good results in other areas, is understandable. There is, however, a considerable difference between reduction to components and reduction to sequence. One is essential, the other is a failure of imagination. Given the many errors being perpetrated in the modularized NLP process for extraction of meaning from text, the reliabilities being quoted in technical papers are surprisingly high. If the reliabilities quoted were weighted by the seriousness of failure in individual cases to reflect the perversity of outcome, where simple text for a healthy patient is reliable and slightly less simple for an ill patient is atrocious, a different picture would probably emerge. A radically different approach is necessary, one more in keeping with the properties of the apparatus generating the text, if we are to attain reliabilities commensurate with the importance of the medical bioinformatics purpose.
References
[1] L. Smith, T. Rindflesch and W.J. Wilbur.
MedPost: A Part of Speech Tagger for BioMedical Text
[2] Rabiner, L.W. (1988). A Tutorial on Hidden Markov Models
and Selected Applications in Speech Recognition. Proc. of the IEEE 77, 2, 257-286.
[3] Santorini, B. (1990). Part-of-speech Tagging Guidelines for the Penn Treebank Project
See