QQQQ is a heavily traded index of high-tech company stocks on the NASDAQ exchange. The share prices of these stocks rise and fall in response to rumour, company success and market-wide effects. A large part of the index movement is to do with expectations far into the future, expectations that may never materialise. Expectations can be built up by short term news - retail sales up, market up. But bad news may be perceived as good – retail sales down means less chance of an interest rate rise, so the market rises. To predict the QQQQs one day ahead so we can trade successfully, we need to bring together many effects. Here are six of them:
| Model the companies. We need to model each of the important companies in the index, and be able to predict both the market expectation of profit and the likely actual profit or analyst guidance the day before it is announced. | |
| Model the events. The market responds to release of a variety of economic data - inventory, labor, retail sales. We need a calendar of these events, and models predicting the likely outcome. | |
| Model the expectations. The market has expectations of many things that are outside the actual companies in the index – the price of oil, a slack period around Labor Day, the expectation of an interest rate change, growth in a sector based on one company’s success, or the market may be desperately waiting for some good news. Some of these expectations may not be rational, but they need to be carefully modeled, as their effect is often larger than the changes due to actual company results. | |
| Put it all together. Each of these elements is important, but it is more important that they all be connected, as each affects the others. There is no simple formula here. There is a lot of spadework required to model the companies, but this would be of little value without modeling of expectation. Only when it is all put together do the parts come to have predictive value – each part by itself may predict the opposite of the whole. | |
| Jump out fast. No matter how much analysis is built in, events will occur which make the analysis wrong. The system needs to evaluate the situation and undo any position invalidated by the event. | |
| Continuous Refinement. The task has two parts – building and maintaining the models and building the expertise in a small team to refine them and keep them continuously up to date. |
The system is built on the premise that a large number of small recent guesses is more accurate than a few large guesses, as long as all the small guesses are consistent with each other. This doesn’t mean that areas of the model don’t move in opposite directions, but it does mean that over an appropriate timescale the different influences balance out – the market forgets them, as they become built into the price of the QQQQs.
Model the Companies
We build outline models, both of the companies and their industry sectors.
An industry model is responding to the predicted economy (the economy is defined broadly enough to include manufacturer and consumer sentiment), and to events within the companies that make it up (not necessarily just the companies in the QQQQs, as very good or very poor results by companies in the sector but outside the index influence the expectations of the sector).
NASDAQ stock prices are typically valuing a company on how it will perform years in the future. Some companies in the index have yet to make a profit, and their stock price is based mainly on expectations. This gives the QQQQ index its attraction – large variations in price from day to day, allowing large trading profits to be made.
A detailed financial model of each company – involving its cashflow, EBITDA, market share – would be of little use by itself. All it would show is that most companies in the index seem overvalued. Instead, we need to model the basis for the current stock price, so we can estimate the trajectory of the stock over the next little while. The basis may be – a considerable fall in cost as manufacturing matures, leading to a rapid expansion of the market, even the likely appearance of a new, as yet unknown, market. These notions, which may only exist in the minds of hopeful stock analysts, can then be connected to economic or technology influences. A stock that is going to be the "next big thing" turns to dust because a new generation of technology will already overtake it before it is introduced. A stock that keeps missing its targets, until the market gives up on it.
The company models predict the outcome of events for the company. Some of these events may be close – a profit announcement next week, others are a long way off – the bluest of blue sky companies may be priced on possible profits five years in the future. The models are driven by global, sector and individual company expectations, and are used to estimate both outcome and expectations, so we are continuously iterating in a circle. The models also need to give direction when we have an unexpected event – a profit downgrade, say.
Model the Events
The events that come around like clockwork – the retail sales, the Fed board meetings. We need to have a position on each of these – we have to both second guess what the figures will be , and how the market will respond, and how quickly, which means we need more than
Retail sales up 0.5 %, market expects 0.9%
We also have to estimate how much the particular figures are supporting the market, and the interaction of conflicting signals – retail sales up, building approvals down.
Model the Expectations
This is the irrational part of the model. The detailed rational modeling is necessary to predict a likely outcome, but expectations exceeded or unmet dominate how much the market changes in response to an event. If analysts and traders have built up expectations that turn out to be unfounded, they are likely to turn more savagely than they should, and the correction overshoot. The expectations model needs to track the underlying reality and the expectations that might be inferred from market signals. When these differ too much, a correction can be expected.
Expectations form an input into industry-wide models, and models of individual companies, so the expectations provide a circular connection.
Expectations do not change instantaneously – those of the day trader may, but pension funds have a much slower response. "Bad news travels fast" – if it is bad enough, it certainly does. This allows us to model the speed of change of expectation, and memory of bad events about a stock in the recent past.
Some expectations are geared around what the company does or may do, some are geared around the price, or what it may do. We need to keep these as separate strands.
Expectations have timeframes. For the QQQQs, we only need to predict one day ahead. But to predict one day ahead, we need to have a position on five days ahead, a month ahead. If we expect the market to turn down sometime over the next five days, that affects our estimate of what will happen tomorrow – it gives us something on which to ground our day to day estimation.
Put It All Together
This is the most important part. There is no point building thirty models in five layers which communicate poorly with each other. The models all influence each other, and quite rapidly if the events are important enough. We also have to model the speed with which events influence each other, as this becomes of critical importance when making daily trading decisions. There are layers of speed and depth of response here – the day trader, the holder of a single stock responding to advice from a broker, the large pension and trust funds.
We can’t allow the different models to get out of phase with each other, or the layers to communicate poorly. This dictates how the system is constructed – not as many parts, but as an integrated whole made up of many different kinds of analysis.
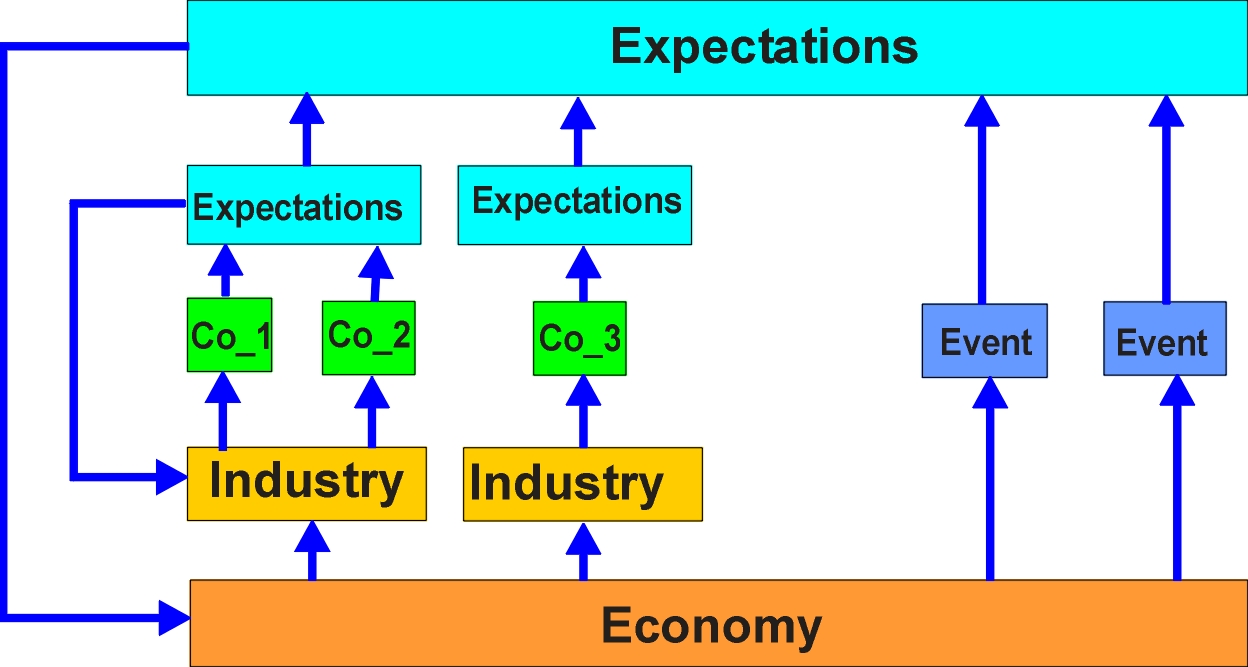
The model is circular, and continually iterates to maintain current expectations.
Continuous Refinement
The model will never be complete. The companies making up the index change, companies start to span across industries, industry groupings become obsolete, new technology creates a new market about which little is known, some economic measure starts to have significance.
What this means is that a small group of people (at least one person, probably two) need to work continuously on the model – assessing why it failed to respond appropriately to something within its range, or working out how some external influence can be brought within its sphere of analysis. The people are the "eyes and ears" of the system, seeing influences it cannot see. They need to guard against the perception that since they guessed right once when the system got it wrong, they can do better without analysis.
When the market is chaotic, and all sorts of influences are impacting on the market, it is easy to see the need for refinement, but usually there is no time to look for subtle influences.
When the market is trending strongly in one direction and the system almost never makes a mistake, there seems little need for continuous work. It usually means there is a tipping point approaching, and the system should be as accurate and as close to the market as possible in its estimation of when the change will occur.
There needs to be a commitment to maintain the system, and the people working with it need to have the approach of relentless improvement – why did we miss that and what can we do about it, rather than just accept occasional failure as part of the prediction process (which it is, but should be kept to an absolute minimum). They need a can-do attitude, in other words.
Other Possibilities
Why Not Just Use People
People can develop a very effective trading strategy, but it tends to ossify with success, and they keep using it when it doesn’t apply any more. It is hard work keeping up with everything, so they tend to keep contact with only a few inputs and guess the rest. Better to have something outside the people that they can keep improving, and others can comment on.
People can walk, but they build cars because you get tired of walking, and chasing the QQQQs is a never ending journey.
Can’t We Track a Trend
Any trend is the combination of several trend components – sometimes they are in sync, sometimes they get out of sync, and then big changes occur. The information is there, just hidden and unknowable. You are better off trying to find causes and estimating them – at least you can then see how some event might affect other events.
Statistics can tell you what happened in the past, but that is not much use for the future. The sun is likely to rise, but which way for the QQQQs? Each gyration is pretty much unique, because the people in the market have a memory too, and will try to avoid or exploit what happened last time. This is the problem with just having every possible input and hoping sense will come out of it over time – traders are making decisions also based on what happened before, and making different ones because of it.
Just Write a Program
You might know what is important today, but you don’t know what will be important tomorrow, so it is hard to know where to start with a program. There are also a lot of pieces involved – economic models, sector models, company models, expectation models, all communicating with each other – not something a program does well. It is much easier to build something where it doesn’t matter where you start, you just put the pieces together and it works out what is important tomorrow, and you can change its structure easily, not spend a year to unpick a program and start again with a better idea. This need for undirectedness rules out programs, expert systems, neural networks, anything that has to be directed to a purpose. There is a purpose, but it is a high level one, and with a directed system you need to know the direction of every piece at the beginning, so predicting the QQQs has to be done some other way.
All or Nothing
Is this an all or nothing situation – until some enormous model is built, it doesn’t work, and can’t be trusted to do anything?
Partly true – it relies on the skill of the model builders and trading operators to augment any areas of the model that are missing – that is, provide supporting input. It would be expected that after six months, the model was handling a large part of the predicting, with human intervention decreasing over time until it became manageable by one or two people continuously engaged in the support process.
See
An Introduction to the Technology