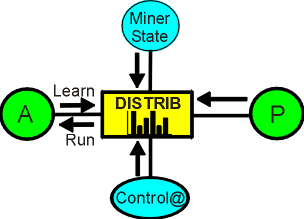
The format of the DISTRIB function is:
DISTRIB( Control@, MinerState, Probability)
The function is usually built automatically by the Data Miner, and provides a range to a variable, indicating the values present in a list, internally constructed during the Learning phase of Web or Data Mining.
The parameters control the operation of the DISTRIB function:
Control@ - if TRUE, the function will respond to the state of the MinerState connection, either storing information or outputting it. If not TRUE, the operator does nothing.
MinerState - the MinerState can be Quiescent, Learning or Running, or an intermediate state. If Learning, the information coming in the value pin is constructed into a probability distribution, for later output during the Run state. That is, during the Run state the variable takes on the range found during the Learn state.
Probability - if no Probability is specified externally, the initial value of Probability will be set to 0..100 (indicating a probability of 100%), and the full range will be output at the value pin. Reducing the range of the Probability will reduce the range of alternatives at the value pin, based on frequency of occurrence.
The DISTRIB function handles logical, string and numeric distributions, and creates a distribution with no holes, or nil occurrences, in it.
ABC 25 DEF 12 GHJ 3 XYZ 1
At completion of the learning phase, the strings are ordered in decreasing frequency. A request for all possible alternatives (Probability of 0..100) would result in
ABC, DEF, GHJ, XYZ
whereas a request for a probability of 0..90 would result in
ABC, DEF
If the number of strings would exceed 100, a catchall string of '*' is used.
The contents of the distribution operator can be inspected and edited using the PieceLine interface.