There are many applications where knowing the probability distribution of possible values for a variable would be useful. Many variables used to model real situations do not exhibit a normal distribution, so some means of describing an arbitrary distribution is required. This has been implemented using a list of discrete values or ranges for the "bins" that make up the distribution, and storing the number of hits in each bin of the distribution. The distribution operator needs to operate within the confines of the knowledge network, so it is equipped with connections that allow for its control, and its method of storage is arranged to be both backtrackable and resettable on killing.
Distributions alone would not allow for experiential functions among variables. These are provided by using relation operators, acting as n-dimensional graphs. A change in one distribution can be propagated through the relation to cause change to one or more other distributions.
The probabilistic information which the distributions hold can be used to extract various probability measures - mean, median, most probable, etc. – using an extract operator.
Operator StatesThe distribution and relation operators have logical controls, and they also have a Learn/Run control, which can be in any of five states.
Quiescent – the operator does nothing.
StartLearn – the operator resets its internal storage to its root – in other words, it deletes any list of values it may have had. This behaviour can be overridden, by locking the operator so that all hit counts are removed, but the list of values is retained (keeping the months of the year in order, for example).
Learn – a new value appearing on pin 1 will increment the bin which matches the value (assuming other connections are in an appropriate state). If no bin exists, one will be created. If the limit on bins has been reached, two neighbouring bins with low counts will be merged into a range to free up a bin. The type of the numeric variable – whether integer or real, must already have been nominated, so the appropriate type of range can be created.
FinishLearn – the bins are sorted into a particular order – ascending for numeric, alphabetical or a variety of other orders for distributions of strings.
Run – the operator becomes active and puts out the range of the distribution it contains on pin 1. The range is collapsed to its simplest form – if the list of bins is 1,2,3..10 as integers, then 1..10 would be output.
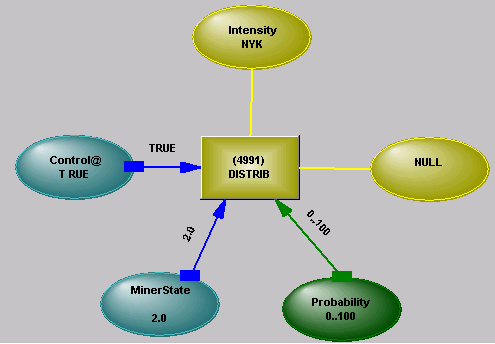
The DISTRIB Operator
The operator has four connections and a stub link:
Pin 1 is connected to the variable acquiring the distribution. In the Learn state, values flow from the variable into the operator, and are recorded. In the Run state, values flow between the variable and the operator in both directions.
Pin 2 is a logical control. If pin 2 is not True, nothing happens, allowing different banks of distributions to be switched on and off.
Pin 3 is the Learn/Run connection.
Pin 4 is a probability connection initially with the range 0..100, meaning that the entire distribution range should be output. Varying the range influences the range of the distribution put out, so that 50..100 would put out only that part of the distribution included between the 50 and 100 percentiles, including fragments.
Pin 5 is a stub link, used to store state information the operator needs to protect from the killing of information that may occur in connected links.
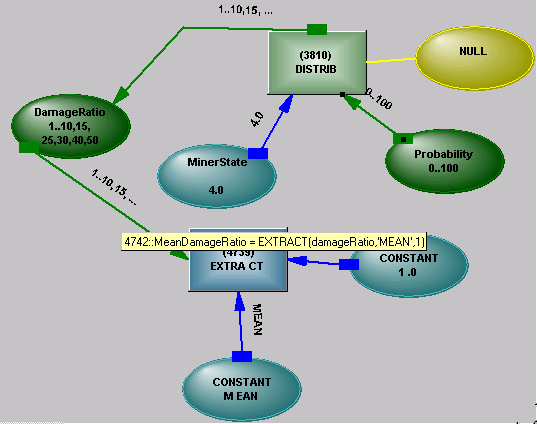
The Network Display shows a distribution operator connected to the variable named Intensity. The state of Intensity is NYK (Not Yet Known), Control state is True, and the Learn/Run state is Learn (2.0). The link with the variable labelled NULL is a stub link.
The operator can be filled by
Data Mining a database – the values in columns in a table will be used to set variables in a model. These variables, or others connected through analytic structure have a distribution operator connected to them. The necessary sequencing of states is handled by the Data Miner.
Loading data directly from a file – the contents can also be dumped into a file, and the file edited. Ranges for bins can be nominated.
Drawing an ad hoc distribution and having this converted into an internal representation.
Incremental updating, where the distribution is updated in operational mode. After being used in Run mode to analyse a transaction, it is switched to Learn mode to store the input value for the particular transaction, which may change the probability distribution for further transactions. This is particularly effective when the operator is given a presumed "starter" distribution and "learns on the job".
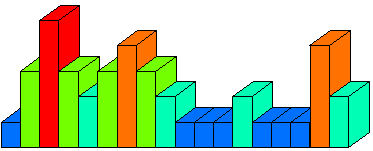
The diagram shows the contents of a distribution.
The Interaction of a Variable and a Distribution
With no other values present, the distribution will put out its full range to its associated variable. If a reduced range comes in on the variable from some other source, this will flow into the distribution and reduce the range of a "current copy" of the distribution. Other operators connected to the same variable and for whom a changed distribution is relevant are also notified (the other operators will also receive the change in variable range, but their operation needs to be synchronised with the change in distribution, which may occur after their receipt of a change in variable range).
If the value of the variable is "killed" by some other source (that is, set to NYK), the distribution will revert to the full distribution and output that to the variable.
The RELATION Operator
The distribution operator by itself would have limited usefulness, as the distributions of many variables depend on their relations with other variables. The relation operator makes this connection. For example, a Damage Ratio for buildings subject to earthquakes may depend on Intensity, Building Type and Duration (of shaking).
The relation operator has three base links, plus as many links as there are variables it is connecting through the relation (to a maximum of ten variables):
Pin 1 is a Control pin. This will usually be set False while distributions are in a Learn state.
Pin 2 is a Learn/Run connection. If in Learn state, the internal graph is updated based on the values on the variables. The positions of the values in the distributions that match the values on the variables are used as an index into a hypercube (implying that the distributions must have been in Learn state with these same values prior to this). The hypercube is stored in a sparse mode, storage only being allocated when a hit needs to be recorded in a particular region of the hypercube. In Run mode, the relation operator does nothing, acting only as a repository for the distribution operators.
Pin 3 is a stub link, storing state information.
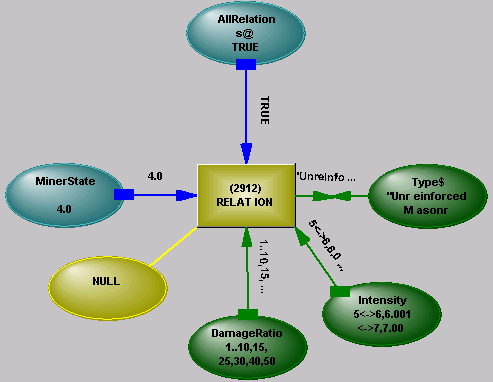
The operator can be filled by
Data Mining a database – the values in columns in a table will be used to set variables in a model. These variables, or others connected through analytic structure have a relation operator connected to them. Distribution operators are also required, to provide indexing for the hypercube.
Loading data directly from a file – the contents can also be dumped into a file, and the file edited
A relation can be built from ad hoc distributions – a calculation is performed to estimate where in the hypercube points must fall to satisfy the constraints imposed by the distributions.
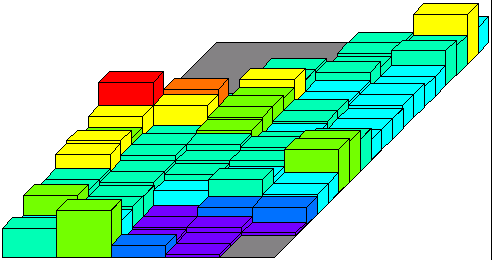
An example of the contents of a relation – two dimensions (Intensity in the x-direction and DamageRatio in the y-direction) of a three dimensional relation are shown, with hits for all types of ConstructionType being summed.
Changing the range on either or both of Intensity and ConstructionType will result in a recalculation of the distribution for DamageRatio, and vice versa (that is, the distributions held in the relation, and still within range on the other dimensions, are summed to give the remaining distribution).
Example
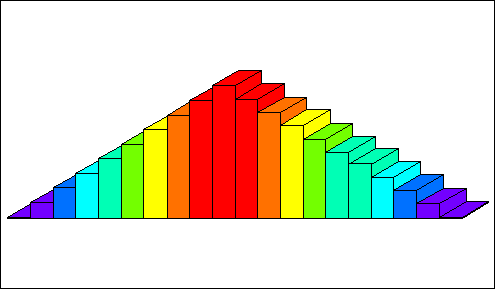
The variable x has the distribution
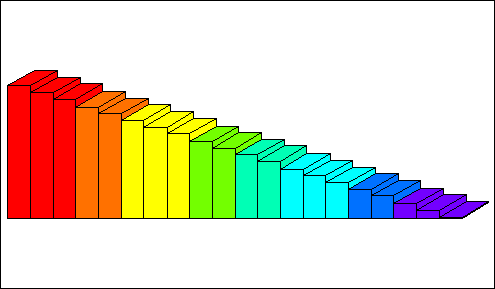
The variable y has the distribution
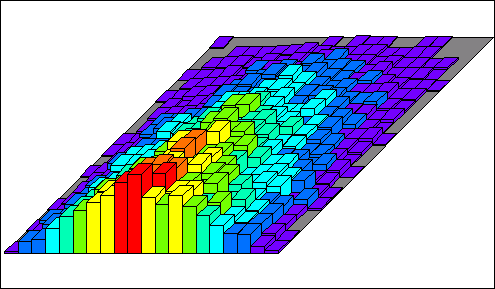
A relation is constructed between them, using the distributions as constraints.
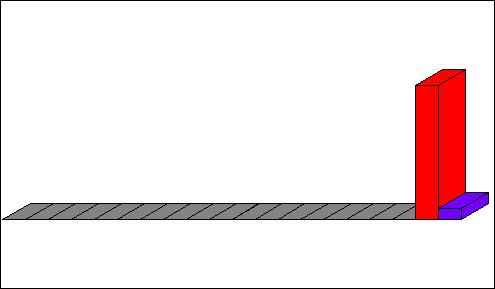
The range of x is constrained

The relation changes to
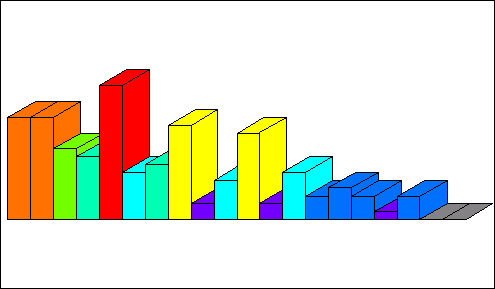
The distribution of y changes to (note the change in range, as well as the change in shape)
Cutting of the distribution through the relation needs to be undone, if the distribution that initiated the cutting is reset. The cutting is also backtracked when appropriate. A distribution may be subject to cutting from several relations at once, and several distributions may be cut simultaneously through a relation, requiring coordination of several propagations. No cutting through a relation will occur if any of the distributions has a NYK state on its Pin 1.
Extraction of Statistical Measures
Other Uses for Distributions
If logical to numeric operators such as EQUALS, LESS etc.are performing comparisons on two numbers, and the operators have been marked as Bayesian, they will check for distributions being present, and use those in the calculation. As an example,
IF X > Y ....
For the previous example, both X and Y had ranges of 1..20, but their distributions were different, so a Bayesian value greater than 0.5 would be found for the comparison (and the comparison would be retriggered if either distribution changed).
Other Related Operators
An operator which is similar to a relation, but sums a value such as money into its cells instead of hits. It could be used to analyse sales by region and product line.
Functions as a many-axis predicate, allowing product attributes in ten or fifteen dimensions to be specified for a product, and close products searched for in a large, very sparse hyperspace.
ConclusionDistributions and relations in the structure permit the integration of readily updateable experiential information in what otherwise would be an exclusively analytic structure. Their flexibility in a wide variety of uses springs from the use of ranges to form their bins, and the level of integration with the rest of the network.