The Data Miner can be used in three ways:
| To fill distributions and relations for immediate use in operational systems | |
| To build higher level relations based on what is found directly in the database | |
| To clean data during extraction for a Data Warehouse | |
| To be used merely as a database access mechanism, to pump data through a model |
The description that follows assumes the data is being converted into distributions and relations for higher level use.
The Data Mining process occurs in four stages:
The miner can be connected to any database, either directly through BDE (Borland Database Engine) or through ODBC - Microsoft's link to remote databases on any platform. The visible connection to the tables in the database is made using Combo boxes and a database grid. The user can peruse any particular table using the table navigation tools.
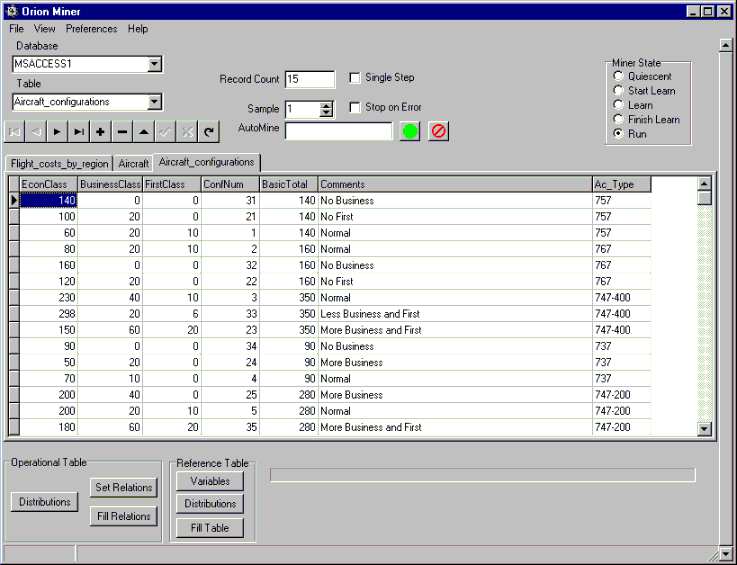
The Miner automatically adds logical environments to the model to agree with table names. The Set Distributions button on the Miner allows the user to nominate which variables should have distributions - some table columns contain random data such as Account Name, and are unsuitable for mining.
Any known business structure should be added - descriptions of how profit or profitability are derived, tax regime, exogenous variables such as power costs, etc. There may also be structure in the database that links records in a table - routes linking flights in an airline's database, divisional structure linking diverse retail operations. Analytic structure can be used to link records. For example, flights in separate records which represent legs of a route can be linked together using
RouteNumber = FlightNumber + FlightNumber MOD 2
In this way, all flights on a route can be directed to accumulate relationships relevant to the route.
In some cases, it may be easier to add analytic statements once the distributions and relations are active, or even while a mining stage is in process, so that the effect of statements on individual records can be seen.
The Set Distributions button creates distribution operators on all table columns and model variables that do not have values set. A dialog will come up, allowing some columns to be ignored. The distribution operators will store the range and frequency of occurrence of all variables when dataflow from the database table is instigated after the distribution operators are created, using the Fill Distributions button.
The Set Relations button allows the user to nominate the relations among variables to be built. Depending on number of combinations, some of the variables may be grouped into multi-dimensional groups. Most relations will be between a pair of variables. Groups can be nominated one by one, one variable can be linked to all others through relations, or all to all (can be expensive for large column numbers).
The Fill Relations button instigates dataflow from the database table into the relations, causing probability maps of the relationships to be created based on correlation at inputs.
Once the information storage is completed, the user has a model that is able to "slice and dice" information in many different ways, using its distributions and relationship graphs to do so. Calculations on the information range from the mean of a distribution to finding relations between relations that have a common dimension, or even common members in different base sets.
The user interface to the content6s of the memory operators is a powerful means of understanding relationships in the model, before and after the Data Mining stage.
The user can now nominate a variable, corresponding to a table column or some analytic description in the model, as the focus of the search. The miner seeks relations that will allow it to predict the desired output. A simple example:
A + B = C
The variable C is nominated as the output. A and B are random variables. The miner finds relations
A vs B
A vs C
B vs C
It observes the existing correlation error, then attempts to combine the relations leading to C in various ways. The combination operation on the relations is performed without using the database - the relation between A and B is used to pinpoint combinations of A and B that occur in the database. There is some uncertainty, but enough accuracy to indicate whether the relation, if built, would reduce the correlation error.
The Miner tries
A - B vs C
and finds the correlation error increasing. It tries
A + B vs C
and finds a reduced correlation error. It then tries multipliers, as
2.0 * A + B vs C
A + 2.0 * B vs C
and finds more error than its initial combination, so builds the structure D = A + B and, using the database, fills the distribution on D and the relation D vs C. It can find no further combination which would reduce the current correlation error, so it stops.
The Miner will often need to assemble pieces of different relations to provide an accurate prediction over the range of the output.
Each step in the mining process has analytic support. The user can monitor the Miner's progress and can observe the improvement in prediction available from each stage of construction. The user can also refine the relations found, adding 'ad hoc' distributions and generate relations using the Stochastic Editor.
Mining of Knowledge - a discussion paper
Mining of Knowledge - a presentation